
แม้ว่า AI จะก้าวหน้าอย่างรวดเร็ว แต่ DeepSeek-R1 ก็สามารถสร้างความตกตะลึงให้กับทุกคนได้ โดยใช้เวลาไม่นานในการพัฒนา AI ที่ล้ำสมัยและปฏิวัติวงการให้ราคาถูกลง เข้าถึงได้ง่ายขึ้น และที่สำคัญที่สุดคือเป็น Open-source ซึ่ง DeepSeek-R1 เป็น โมเดล AI ตัวใหม่ล่าสุดที่ถูกพัฒนาขึ้นมาเพื่อแข่งขันในด้านการใช้เหตุผล ที่พัฒนาโดยบริษัท Deepseek ของจีน บทความนี้จะพามาเจาะลึกเจ้าตัว DeepSeek-R1 กับ DeepSeek-R1: Open-Source AI ที่กำลังเปลี่ยนเกมโลกเทคโนโลยี
Open Source ราคาไม่แพง ที่ทุกคนสามารถเข้าถึงได้
จุดแข็งที่สำคัญของ DeepSeek-R1 คือเป็น Open Source โดยเผยแพร่ภายใต้ใบอนุญาต MIT ทำให้เทคโนโลยีและการวิจัยเผยแพร่ต่อสาธารณะ สาธารณะ นอกจากนี้ DeepSeek-R1 ยังเผยแพร่เอกสารการวิจัยอีกด้วย ทำให้สามารถนำผลการวิจัยไปทำซ้ำและลองใช้ให้มีการใช้งานวิธีการใหม่ ๆ
Paper: https://arxiv.org/pdf/2501.12948
- สำหรับการจำลองทั่วไป: Open R1 กำลังจำลองกระบวนการฝึกอบรมทั้งหมด https://github.com/huggingface/open-r1
- และ TinyZero กำลังจำลองวิธีการ สำหรับจุดประสงค์เฉพาะ: https://github.com/Jiayi-Pan/TinyZero ซึ่งได้รับการ Optimize สำหรับงานนับถอยหลังและการคูณ และได้รับการอบรมด้วยราคาเพียง 30 ดอลลาร์สหรัฐ
นอกจากนี้ DeepSeek-R1 ยังมีความคุ้มต้นทุนมาก: การฝึกโมเดลมีค่าใช้จ่ายน้อยกว่าคู่แข่งถึง 95% และ API มีค่าใช้จ่ายเพียง 0.55 ดอลลาร์สหรัฐต่อหนึ่งล้าน Tokens ซึ่งคิดเป็น 2% ของต้นทุน OpenAI O1 ซึ่งต้นทุนที่ก้าวล้ำนี้จะสามารถทำให้เกิดการเปลี่ยนแปลง ให้การใช้โมเดลการให้เหตุผลเข้าถึงธุรกิจต่าง ๆ ได้มากขึ้น
ยิ่งไปกว่านั้น DeepSeek-R1 ยังก้าวไปอีกขั้น ด้วยการนำเสนอโมเดลที่กลั่นกรองแล้ว พร้อมความสามารถในการใช้เหตุผลที่แข็งแกร่ง ซึ่งทำงานบนฮาร์ดแวร์ขนาดเล็กกว่ามาก ซึ่งก็คือ O1-mini บนคอมพิวเตอร์ของคุณ โดยพวกเขาได้เปิดตัวโมเดลตั้งแต่ 1.5B ถึง 70B ที่สามารถมอบประสิทธิภาพระดับ GPT-4 สำหรับงานส่วนใหญ่บน GPUs ได้เลย
การออกแบบที่ล้ำสมัย: MoE และ RL มีส่วนสนับสนุนอย่างมาก
DeepSeek-R1 นำเสนอสถาปัตยกรรมแบบ Mixture-of-Experts (MoE) ที่น่าประทับใจ แม้ว่าจะมี Parameter ทั้งหมด 671 พันล้านตัว แต่มีเพียง 37 พันล้านตัวเท่านั้นที่เปิดใช้งานต่องาน ซึ่งช่วยให้ทำงานได้อย่างมีประสิทธิภาพโดยไม่กระทบต่อประสิทธิภาพ เนื่องจากโมเดลนี้ใช้ Parameter เฉพาะสำหรับงานและความสามารถเฉพาะได้
แนวทางการฝึกอบรมของ DeepSeek-R1 ยังมีความแปลกใหม่มาก แม้ว่าหลักสูตร LLMs ส่วนใหญ่จะใช้ SFT เป็นหลัก แต่ DeepSeek-R1 จะเน้นที่ RL มากกว่าและ SFT ขั้นต่ำ ซึ่งรวมถึง:
- DeepSeek-R1-Zero: เป็นโมเดลแรกที่ได้รับการฝึกด้วย RL โดยเฉพาะ ซึ่งช่วยให้สามารถพัฒนาทักษะการใช้เหตุผลขั้นสูงได้โดยอัตโนมัติ เช่น Self-verification และการใช้เหตุผลแบบ Chain-of-Thought (CoT)
- DeepSeek-R1: สร้างขึ้นจาก R1-Zero โดยผสานรวมชุดข้อมูล “Cold Start” ที่ผ่านการคัดสรรและการปรับแต่ง RL หลายขั้นตอน วิธีนี้ช่วยให้สามารถอ่านได้ง่ายขึ้นและแก้ไขปัญหาต่าง ๆ เช่น การผสมภาษา ส่งผลให้ได้แบบจำลองที่ละเอียดและมีประสิทธิภาพมากขึ้น
- GRPO: เป็น Algorithm ใหม่ที่ช่วยปรับปรุงคุณภาพ Outputs ของ DeepSeek-R1 ด้วยการสร้างการตอบสนองหลายรายการ ประเมินความแม่นยำและรูปแบบ และเสริมผลลัพธ์ที่ดีที่สุดเพื่อประสิทธิภาพที่เชื่อถือได้มากยิ่งขึ้น
สำหรับ DeepSeek-R1 นั้น โดยพื้นฐานแล้วมีดังต่อไปนี้:
- เริ่มต้นด้วยข้อมูลที่กำหนดเองและผ่านการคัดสรรอย่างรอบคอบ สำหรับขั้นตอน Cold Start ซึ่งทำให้โมเดลทำงานได้ดีขึ้นในขั้นตอน RL และมี Tokens เฉพาะทางสำหรับการคิด
- GRPO RL Algorithm เน้นที่ความสอดคล้องของภาษาและความแม่นยำ เพื่อเพิ่มประสิทธิภาพการใช้เหตุผล ซึ่งทำหน้าที่เป็นปัจจัยสำคัญเบื้องหลังความสามารถในการใช้เหตุผลขั้นสูงของโมเดล
- ใช้การสุ่มตัวอย่างการปฏิเสธและปรับแต่งอย่างละเอียดด้วยข้อมูลที่กรอง จากแบบจำลองจุดตรวจสอบ R1 และตัวอย่าง DeepSeek v3 วิธีนี้ทำให้มีความรู้เกี่ยวกับ Domain ที่หลากหลาย รวมถึงการเขียนและความรู้ทั่วไป ทำให้แบบจำลองนี้มีประโยชน์และมีความรู้มากขึ้น นอกเหนือจากความสามารถในการใช้เหตุผลที่แข็งแกร่ง
- RL Algorithm สำหรับสถานการณ์ต่าง ๆ พร้อมโมเดลรางวัลที่ปรับแต่งให้เหมาะกับข้อมูล ช่วยเพิ่มประโยชน์และทำให้มั่นใจได้ว่าจะตอบสนองได้ปลอดภัยและเชื่อถือได้มากขึ้น
เทคนิคการฝึกอบรมนี้ช่วยให้ AI สามารถเรียนรู้และปรับปรุงโดยอัตโนมัติ ลดการพึ่งพาข้อมูลจำนวนมากที่มีการใส่คำอธิบายโดยมนุษย์ ขณะเดียวกันก็มีความชาญฉลาดเพิ่มมากขึ้น
Benchmark Performance: ผู้บุกเบิกรายใหม่
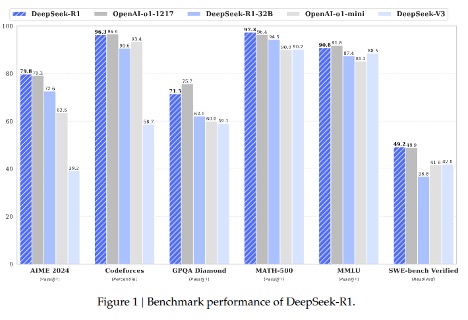
การเปรียบเทียบเกณฑ์มาตรฐานจากเอกสาร R1
DeepSeek-R1 ขึ้นแท่นอันดับหนึ่ง ในการทดสอบประสิทธิภาพต่าง ๆ:
- การใช้เหตุผลทางคณิตศาสตร์: DeepSeek-R1 ทำคะแนนได้ 3% ในเกณฑ์มาตรฐาน MATH 500 ซึ่งสร้างสถิติใหม่
- ทักษะการเขียน Code: อยู่ในอันดับที่ 3 ในเกณฑ์มาตรฐาน Codeforces แสดงให้เห็นถึงความสามารถในการเขียน Code ในระดับผู้เชี่ยวชาญ โดยตามหลัง OpenAI ที่ได้อันดับ 96.4 เพียงเล็กน้อย
- AIME 2024: แซงหน้าโมเดล O1–1217 ของ OpenAI เล็กน้อย ด้วยคะแนน pass@1 ที่ 8% เทียบกับ 79.2%
- ความรู้ทั่วไป: ได้คะแนนต่ำกว่า O1–1217 เล็กน้อยใน MMLU (90.8% เทียบกับ 8%) และ GPQA Diamond (71.5% เทียบกับ 75.7%) แสดงให้เห็นถึงจุดแข็งในการใช้เหตุผลมากกว่าการดึงความรู้เพียงอย่างเดียว
- Software Engineering:ทำคะแนนได้ 2% จากเกณฑ์มาตรฐานที่ผ่านการตรวจสอบของ SWE-bench สะท้อนให้เห็นถึงประสิทธิภาพที่แข็งแกร่ง ในการตรวจสอบซอฟต์แวร์
- AlpacaEval 2.0: ได้รับคะแนนประเมิน 6% แสดงให้เห็นถึงความสามารถในการสร้างข้อความเหมือนมนุษย์ที่มีคุณภาพสูง
จุดแข็งของ DeepSeek-R1 อยู่ที่การแก้ปัญหาและการใช้เหตุผล ในขณะที่ O1–1217 ของ OpenAI เป็นผู้นำเล็กน้อยในงานความรู้ทั่วไปและการเขียน Code
เหตุใด DeepSeek-R1 จึงมีความสำคัญ?
- ราคา API ที่เอื้อมถึงของ DeepSeek-R1 และการเข้าถึงฟรี สำหรับการใช้งานส่วนบุคคลทำให้บริษัทใหญ่ ๆ เช่น OpenAI และ Google ตกอยู่ในสถานการณ์ที่ท้าทาย ด้วยตัวเลือกต้นทุนต่ำหรือไม่มีค่าใช้จ่าย User จึงมีแรงจูงใจน้อยลงที่จะจ่ายเงินค่าสมัครสมาชิกหรือ API ราคาแพง
- AGI Glimpses: Self-correction ระหว่างการให้เหตุผลนั้นแสดงให้เห็นถึงรูปแบบหนึ่งของปัญญาประดิษฐ์ หากความสามารถนี้ได้รับการขยายขนาด อาจส่งผลสำคัญต่อการผลักดัน AI ให้ก้าวไปสู่ปัญญาประดิษฐ์ทั่วไป ซึ่งอาจนำเราเข้าใกล้ AGI มากขึ้น
- ข้อจำกัดด้านการประมวลผลและ GPU ของจีนทำให้เกิดการพัฒนาแนวคิดใหม่ในด้าน AI เนื่องจากการเข้าถึงโครงสร้างพื้นฐานขนาดใหญ่มีน้อยลง จึงมีแรงจูงใจมากขึ้นที่จะค้นหาวิธีการฝึกอบรมที่มีประสิทธิภาพมากขึ้น
- การปฏิวัติการประมวลผล: หลักฐานที่พิสูจน์ว่า Architectures ชาญฉลาดและมีประสิทธิภาพ สามารถคุ้มต้นทุนได้มากกว่า Brute-force Scaling
- ช่องว่างระหว่าง AI โมเดลแบบ Open Source และ Closed Source กำลังแคบลงอย่างรวดเร็ว ในเวลาเพียงไม่กี่เดือน โมเดล Open Source เช่น DeepSeek-R1 อาจตามทันหรือแม้กระทั่งเทียบเคียงประสิทธิภาพของโมเดล Closed Source ได้
O1 เปิดตัวก่อนกำหนด 3 เดือนที่แล้ว และถือเป็นนวัตกรรมใหม่ในขณะนั้น อย่างไรก็ตาม ปัจจุบันมีทางเลือกแบบ Open-source อย่าง DeepSeek-R1 เกิดขึ้น ซึ่งนำเสนอตัวเลือกที่คุ้มราคากว่ามากสำหรับทั้งการฝึกอบรม
อนาคตของ AI
DeepSeek-R1 ถือเป็นก้าวสำคัญในการพัฒนา AI แบบ Open-source โดยให้เหตุผลที่ดีขึ้น ความสามารถในการแก้ปัญหาที่ดีขึ้น และคุ้มต้นทุนมากขึ้น ทำให้เป็นทางเลือกที่น่าสนใจมาก สำหรับโมเดลที่เป็นกรรมสิทธิ์ของบริษัทขนาดใหญ่ แนวทางที่สร้างสรรค์และประสิทธิภาพที่น่าประทับใจของ DeepSeek-R1 ท้าทายความต้องการในการพัฒนาโมเดลแบบปิด ที่ต้องใช้ทรัพยากรอย่างจำกัด
ในขณะที่ AI ยังคงพัฒนาอย่างรวดเร็ว DeepSeek-R1 เป็นตัวอย่างว่าความพยายามแบบเปิดและร่วมมือกันสามารถขับเคลื่อนความก้าวหน้าและจุดประกายความคิดสร้างสรรค์ได้อย่างไร นอกจากนี้ยังทำหน้าที่เป็นเครื่องเตือนใจว่าแม้จะมีทรัพยากรที่จำกัด แต่ความคิดสร้างสรรค์ก็สามารถเติบโตได้ ช่องว่างระหว่าง AI แบบ Open-source และ Closed-source กำลังลดลงอย่างรวดเร็ว ซึ่งพิสูจน์ให้เห็นว่าโมเดล Open-source สามารถแข่งขันในระดับสูงสุดได้
Key Takeaways
- DeepSeek-R1 เป็นโมเดล Open-source ที่แข่งขันโดยตรงกับระบบ AI ที่เป็นกรรมสิทธิ์ชั้นนำ
- การฝึกอบรมและการใช้งานนั้นมีราคาถูกกว่าอย่างมาก จึงช่วยลดอุปสรรคในการเข้าถึง
- ใช้เทคนิคการฝึกอบรมที่สร้างสรรค์ เช่น การเรียนรู้แบบเสริมแรง (RL) และสถาปัตยกรรมแบบผสมผสานของผู้เชี่ยวชาญ (MoE) เทคนิคเหล่านี้ช่วยเพิ่มความสามารถในการใช้เหตุผล ประสิทธิภาพ และความสามารถในการปรับตัว ทำให้แตกต่างจากโมเดล AI ดั้งเดิม
- โดดเด่นในงานที่ต้องใช้การใช้เหตุผลอย่างเข้มข้น เช่น คณิตศาสตร์และ Software Engineering และมอบประสิทธิภาพที่น่าประทับใจในพื้นที่ที่ต้องการการแก้ปัญหาที่ซับซ้อนและการคิดเชิงตรรกะ
- ดูเหมือนว่า Open Source จะตามทันได้ โดยช่องว่างระหว่าง Open-source และ Closed-source ลดลงเหลือเพียง 3 เดือนเท่านั้น
และทั้งหมดนี้ก็คือ DeepSeek-R1: Open-Source AI ที่กำลังมาเปลี่ยนเกมโลกเทคโนโลยี
เมื่อ หางาน IT ให้ ISM Technology Recruitment เป็นอีกหนึ่งตัวช่วย เพื่อให้คุณได้ “ชีวิตการทำงานในแบบที่คุณต้องการ” เพียงส่ง Resume มาที่นี่
ISM เชี่ยวชาญในธุรกิจ IT Recruitment & IT Outsourcing โดยเฉพาะ ได้เปิดทำการมาแล้วกว่า 30 ปี มีพนักงานทุกสายและทุกระดับทางด้าน IT ที่ได้ร่วมงานกับลูกค้าองค์กรใหญ่ที่มีชื่อเสียงและบริษัทข้ามชาติมากมาย
Source: https://medium.com/@soaltinuc/